Existing Score Distillation Sampling (SDS)-based methods have driven significant progress in text-to-3D generation. However, 3D models produced by SDS-based methods tend to exhibit over-smoothing and low-quality outputs.
These issues arise from the mode-seeking behavior of current methods, where the scores used to update the model oscillate between multiple modes, resulting in unstable optimization and diminished output quality.
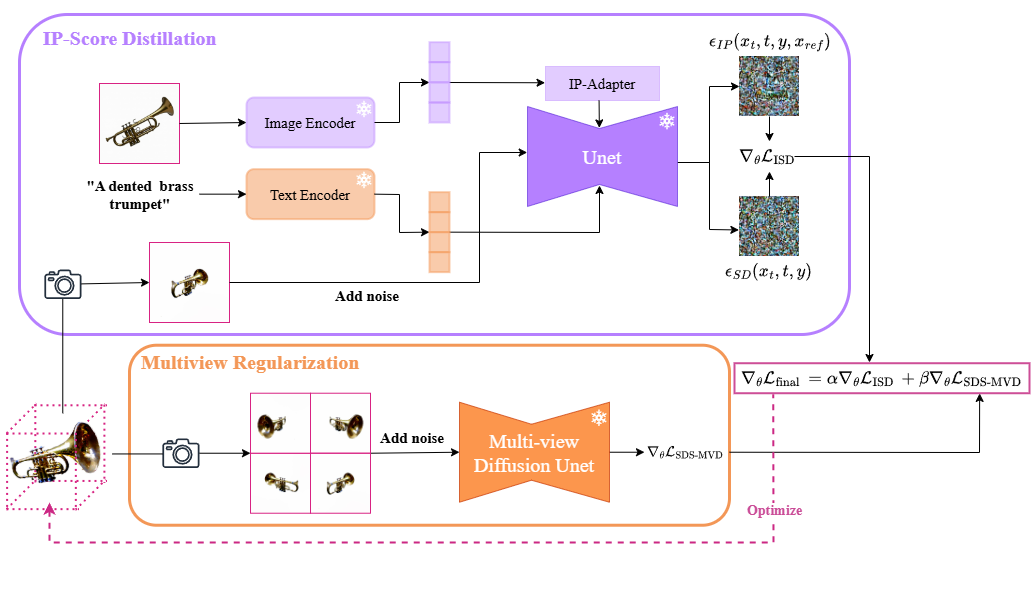
To address this problem, we introduce a novel image prompt score distillation loss named ISD, which employs a reference image to direct text-to-3D optimization toward a specific mode.
Our ISD loss can be implemented by using IP-Adapter, a lightweight adapter for integrating image prompt capability to a text-to-image diffusion model, as a mode-selection module.
A variant of this adapter, when not being prompted by a reference image, can serve as an efficient control variate to reduce variance in score estimates, thereby enhancing both output quality and optimization stability.
Our experiments demonstrate that the ISD loss consistently achieves visually coherent, high-quality outputs and improves optimization speed compared to prior text-to-3D methods, as demonstrated through both qualitative and quantitative evaluations on the T3Bench benchmark suite.